

AI底层理论和相关思考(下)



独家抢先看
3 大语言模型
谈了这么久,接下来终于可以谈谈现在最火的大语言模型了。回忆一下之前Deepmind CEO的话,他希望找到一种方法解决所有问题,专用神经网络显然还不是最终的目标,离通用人工智能AGI仍然有很长的距离。这时自然语言处理领域NLP的AI有了突破,这个突破其实是AI学习语言过程中的一个副产品。说是副产品是因为人们设定目标只是预测下一个词 Token,但就在这个预测过程中AI学会了推理和思考。其实严格来讲语言就是蕴含了推理思考联想等,所以这个副产品当然是人为设计的。这里意想不到的其实是大语言模型的智能涌现。
预测下一个词下一句话或者一个问题的答案,需要学习大量文章。以前人们都是采用一些例如RNN网络来做预测,预测一个词要先预测之前的所有词以及这些前词之间的关系,随着句子的加长预测会越来越慢。面对海量的文本学习起来非常耗时,因为时序的原因不能充分利用GPU平行计算的能力。这时候一个叫Transformer的神经网络横空出世,优势就是同时在大量GPU核上同时进行计算,简单说就是同时计算每一个词和文章中所有词的关系,这种关系被称为注意力Attention。不太精确的比喻就是把串联电路变成并联电路,这就充分发挥了GPU的优势,进行大规模训练变得可行。
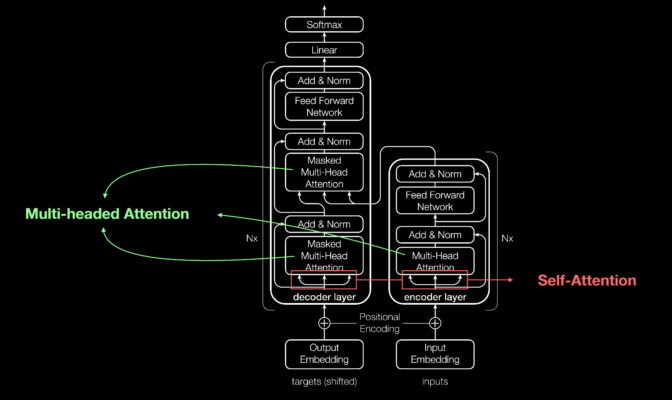
图4: 变型器算法Transformer
在这个基础上人们开始用海量的文本训练AI,经过预训练的AI又引入了强化学习Reinforcement Learning from Human Feedback,而随着神经网络规模的增加,当达到一定规模后出现了智能的涌现。所谓涌现简单说就是AI学会了举一反三,可以回答出之前没有训练过和学习过的逻辑关系。这在数学上类似演绎,结合之前提到的归纳,AI掌握了人类智能的两个基本方法。原因其实也不难理解,就是在强化学习中AI被强制学会和跑通了逻辑链条,类似大脑中出现了新的神经通路,也叫神经可塑性。但神经网络权重的含义还是黑盒。

智能的涌现是一个非常重要的节点,需要大量的训练数据,大规模的GPU集群,这也是AI学者们坚持信念的结果。在这之前智能只是在已知领域做推理。人类大脑包含近1000亿个神经元,接近这个数量级的AI才会有涌现的现象出现,而之前的小模型就没有。智能的涌现是通用人工智能AGI开端,科学家们相信随着计算规模不断扩大,结合视频图像声音等等多模态训练,AGI不再遥不可及。所谓多模态也是通过大语言模型的方法使用非文本数据来训练AI,重点还是统一的算法,不能每个领域单独再开发一套算法,那就失去了通用的意义。一篇叫“苦涩的教训”的文章就是提醒我们不要试图去开发专门算法去解决专门问题。
大模型训练完成后还有很多提升智能的方法,比如Openai的O系列自动构建思维链CoT,Deepseek论文提出的强化学习FL监督微调SFT。还有其他的二次开发的方法,比如增强检索RAG,微调Fine tuning,蒸馏 Distillation,这些方法也是AI在各个专业垂直领域落地的基础。
总结:回顾一下整个计算机编程的发展历程,首先,图灵机通过简单的规则表就实现了复杂的数学运算,从此人们开始基于规则的编程,但这还不属于AI。第二阶段,出现了通过各种统计学和数学方法挖掘大数据规律,这些属于AI范畴,不过还是基于不同的人工方法。 第三阶段,神经网络和深度学习出现,各种领域的AI开始爆发,但也并没有实现通用性。近几年出现了Transformer基础上的大语言模型,在数据规模和模型规模上去之后出现了智能涌现,并且可以延伸到多模态领域,至此通往AGI之门正式开启。
PS: 这篇文章并不是专业学术论文,只是这些年AI学习的一些心得。希望将一些专业AI概念在系统的大框架下做一个梳理,同时尽量通俗的介绍一些AI的重要理论基础。AI原理其实并不复杂,学习AI还是应该避免碎片化盲人摸象或流于表面,否则只能似懂非懂。盲目追求所谓时髦技术赶风口的想法也会导致急功近利。学习AI原理最好的方法就是动手做数学推导然后用代码实现一次,不要调包或API。



